
Technology
In this post, we would like to share a new milestone: our first out-of-CPU implementation of the 1.58-bit approach. By extending our technology beyond CPU into an embedded GPU environment, we demonstrated that an 8B Llama model could run on 8GB Jetson Orin Nano.
Sungmin Woo
March 27, 2026
Edge AI is having a moment. Global semiconductor companies are actively working to implement practical edge AI for their chips. NVIDIA recently introduced TensorRT Edge-LLM for embedded automotive and robotics applications.
Source: NVIDIA GitHub
As a full-stack edge AI solution company, ENERZAi has been delivering powerful AI models that could be utilized in real-world applications though our 1.58-bit technology. Until now, our primary focus has been CPU deployment, especially on Arm CPUs.
In this post, we would like to share a new milestone: our first out-of-CPU implementation of the 1.58-bit approach. By extending our technology beyond CPU into an embedded GPU environment, we demonstrated that an 8B Llama model could run on 8GB Jetson Orin Nano.
TL;DR
Edge AI is quickly moving from simple capabilities to smart AI agents.
We view 8B as the minimum size to implement an AI agent that proactively executes the given tasks and calls the adequate tools from outside if necessary.
But limited memory resources of edge SoCs serve as the biggest barrier for deployment
Powered by our 1.58-bit technology (Quantization and kernel-level optimization), we successfully ran an 8B Llama on Jetson Orin Nano, using only 2.5GB of memory
Capable Edge AI Needs Bigger Models
Edge AI used to be associated with narrower workloads such as anomaly detection, keyword spotting, or basic command control. That is no longer the whole picture.
Recent NVIDIA guidance also encourages the developers to run LLMs, VLMs, and foundation models locally on Jetson, with use cases ranging from personal AI assistant to fully autonomous robots.

Source: NVIDIA
That shift changes what counts as a useful model on edge. If the goal is only to detect an event or trigger a rule, relatively small models may be enough. But once the goal becomes handling operator queries, understanding context, recommending actions, or generating structured summaries, the requirement changes. In our experience, 8B-class models are often close to the minimum size needed to deliver reliably useful performance for those tasks. Larger models can offer further gains, but they quickly become difficult to deploy on embedded systems.
The Real Bottleneck: Memory
When teams first evaluate LLMs on embedded hardware, they often take a look at compute throughput first. In practice, however, memory is usually the harder constraint.
Running an LLM requires far more than storing the weights. It also requires memory for runtime buffers, intermediate activations, and especially the KV (Key-Value) cache. The KV Cache stores intermediate attention data that helps the model focus on the most relevant parts of the input during the generation phase. But it grows linearly with prompt length and becomes a serious bottleneck when the context window reaches millions of tokens.
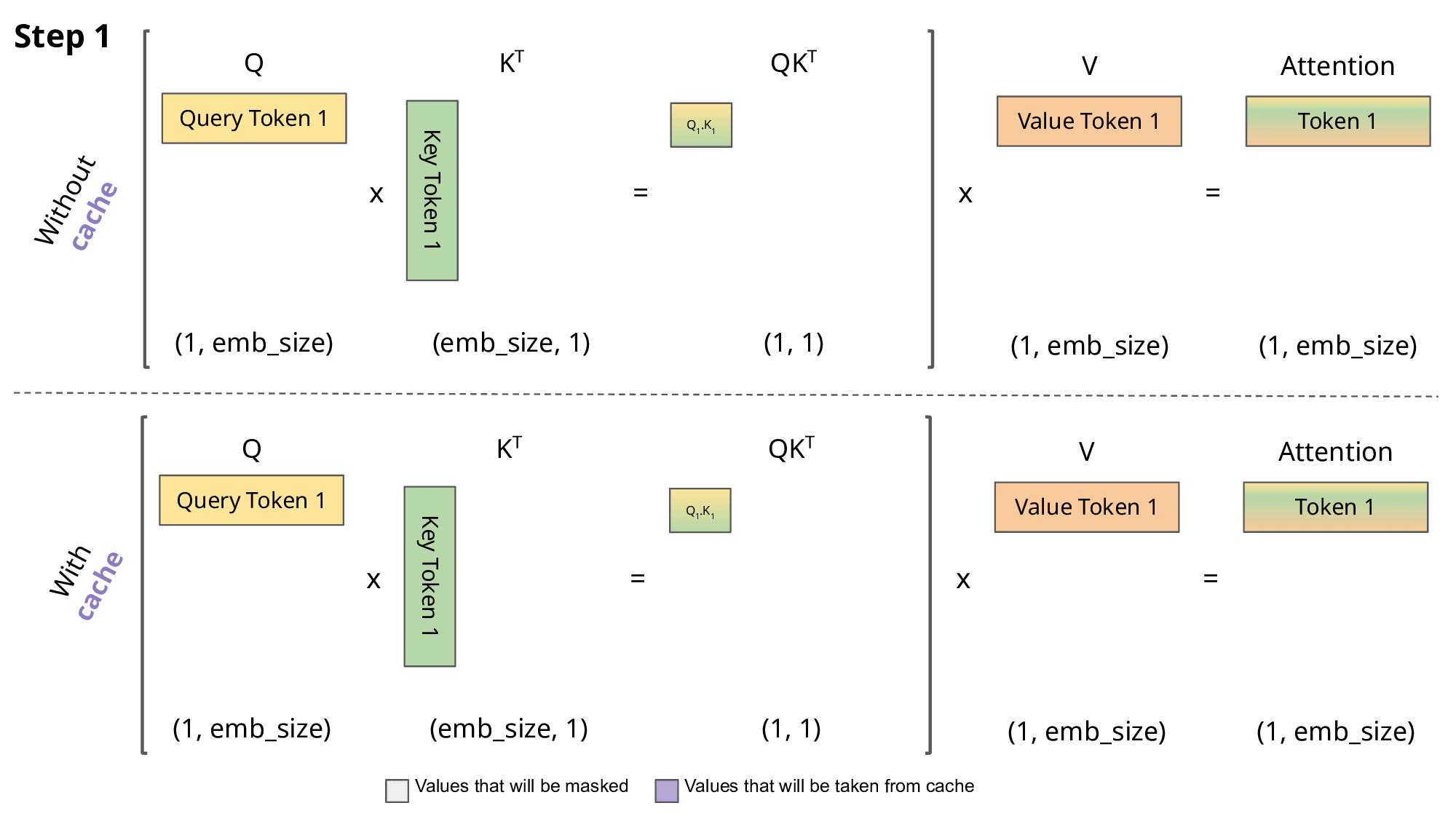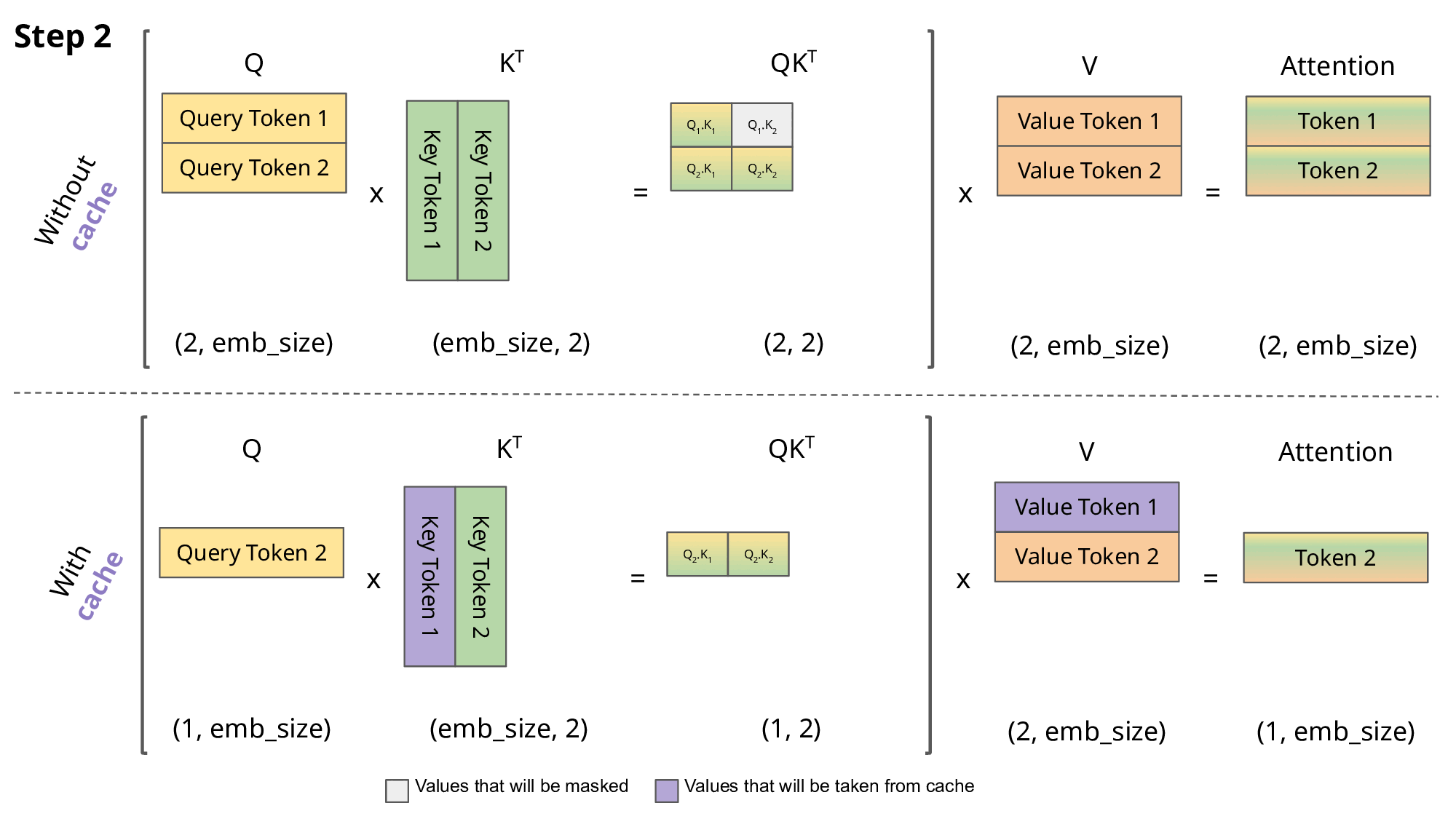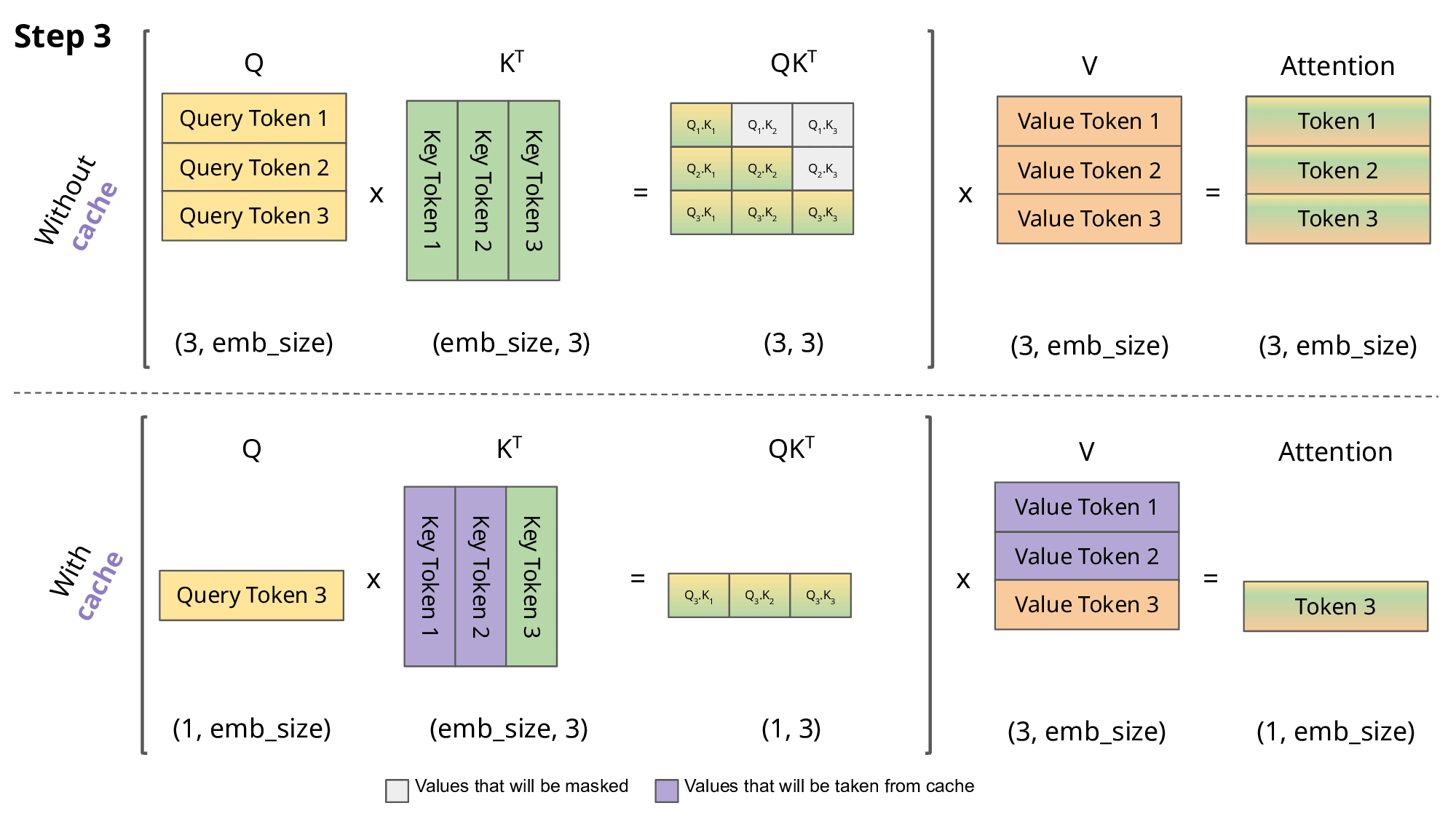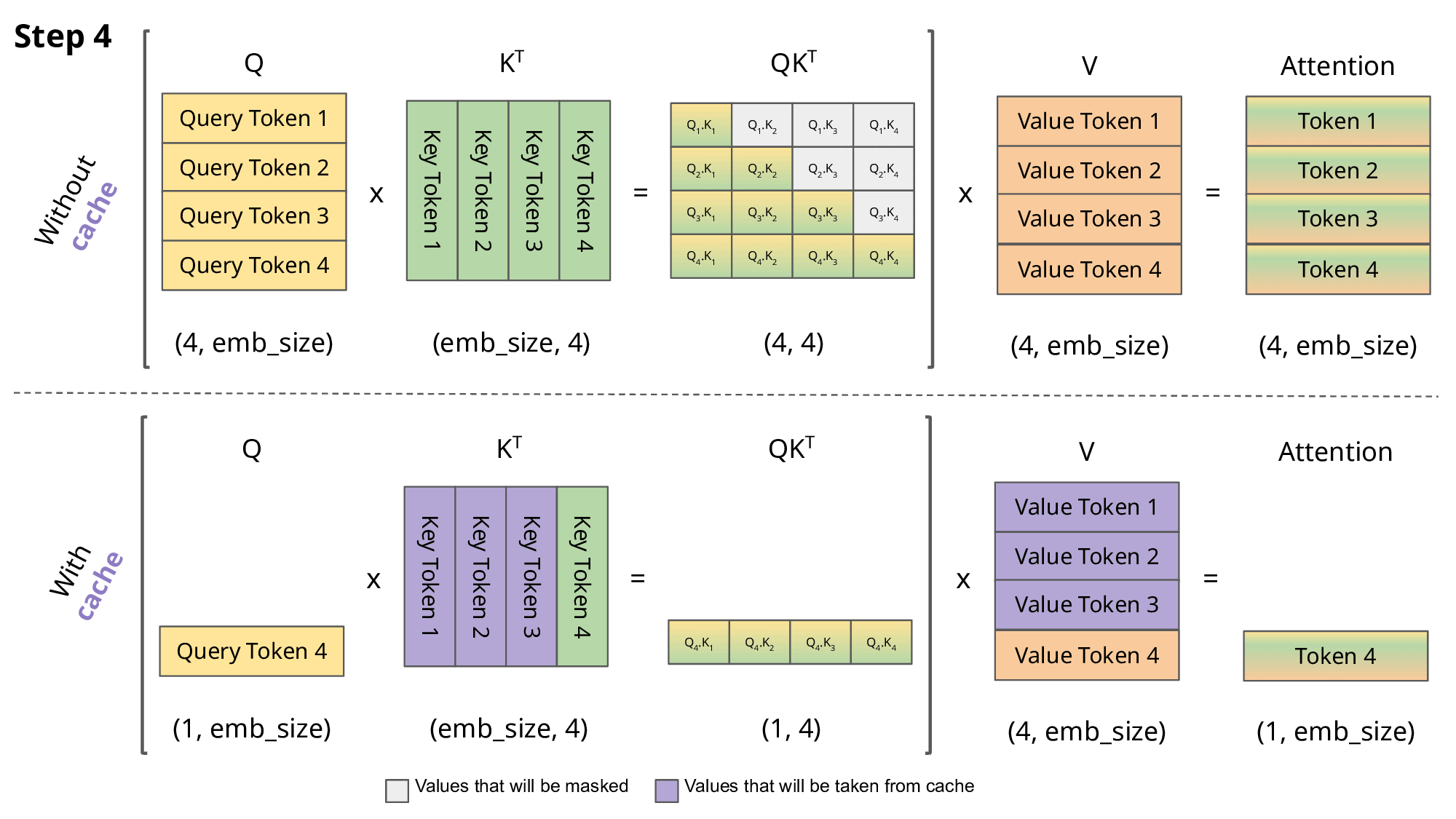
Source: https://medium.com/@joaolages/kv-caching-explained-276520203249
Moreover, memory is not a budget that can be assigned entirely to the LLM. It must be shared across the full application stack, including perception pipelines, networking, telemetry, logging, control logic, and the operating system. This is what makes memory such a hard deployment constraint in edge AI. The model is only one part of the system, but it can easily dominate the memory budget if left unchecked.
Breaking the Memory Wall: Running 8B model on 8GB RAM
Considering this harsh memory constraints, our goal to run 8B LLM on 8GB Jetson Orin Nano was quite challenging. Our baseline, Llama-3.1–8B-Q4 powered by llama.cpp**,** still required 5.2GB of GPU shared memory and 6.8GB of total RAM (peak). Considering that only 7.4GB of memory is actually usable in Nano, that leaves too little room for the rest of the application stack.
Lower Bits, Smarter Execution
Long story short, we managed to run an 8B Llama model on Jetson Orin Nano using only 2.5GB of GPU shared memory and 4.1 GB of total RAM (peak). The model no longer consumes most of the system by itself. Instead, it leaves enough headroom for the rest of the edge stack to coexist, making it possible to move beyond a standalone LLM demo toward a deployable system architecture.
Once again, the answer was our 1.58-bit technology. We quantized the model to 1.58-bit, and implemented custom kernels for the smooth execution of extreme low-bit layers on Jetson.
The goal was not simply to compress the model as aggressively as possible, but to reduce memory pressure where it matters most while preserving usable model quality. We quantized the most memory-intensive compute blocks (primarily linear layers and attention layers) to 1.58-bit precision to reduce memory pressure where it matters most. At the same time, we used a mixed-precision design, keeping embeddings and the LM head in INT4 to preserve model quality. We have already explored how mixed precision enhances inference performance in a previous post.
Optimium 101 (4) — Mixed Precision Inference
On the execution side, we implemented a custom CUDA kernel for INT4 embedding lookup and 1.58-bit GEMM (prefill) & GEMV (generation) layers. And also layer fusions for attention and MLP (Gate+Up projection) to maximize throughput (token/s) with minimum memory usage.
Technical Implications
Lower-cost deployment: If an 8B model can run within a much tighter memory budget, teams are less likely to be forced onto higher-tier hardware just to satisfy the LLM. For example, they can use Jetson Nano for applications where AGX or NX were required.
More capability per device: Instead of using an embedded platform for a single heavyweight model, developers can consider richer on-device pipelines such as fully local voice agent powered by STT + LLM + TTS.
Beyond Llama, Beyond Jetson
While we still believe that CPUs will play a crucial role in AI inference, it is evident that the path to true edge intelligence lies in the ability to run 1-bit models on GPUs and NPUs as well.
This is exactly why we see this project as an important milestone. Our result on Jetson Orin Nano is not just about making one 8B model run on one device. It marks the first time we have extended our 1.58-bit technology beyond CPU into an embedded GPU environment, opening the door to broader deployment across edge hardware.
In fact, we have already begun working on deploying our own 1.58-bit models on Qualcomm Hexagon. Going forward, we plan to keep expanding this effort so that extreme low-bit models can be deployed scalably across diverse hardware platforms including NXP, Synaptics, and more.
ENERZAi at GTC
On March 2026, we had the great chance to present this project in a poster session of GTC!


ENERZAi is actively participating in global exhibitions and conferences to share our research and engage with the wider industry. We are always open to connecting with anyone interested in our technology and solutions!
If your team is building edge AI products on Jetson or other SoC platforms and is facing challenges around LLM memory footprint or latency, please feel free to contact us anytime!