
Technology
이번 글에서는 그 연장선에서 이룬 새로운 이정표를 소개하고자 합니다. 바로 1.58-bit 기술의 첫 비(非)CPU 구현 사례인데요. CPU를 넘어 임베디드 GPU 환경으로 1/58-bit 기술을 확장 적용하여 8B 규모의 Llama 모델을 8GB Jetson Orin Nano에서 구동하는 데 성공했습니다!
Sungmin Woo
March 27, 2026
Edge AI가 빠르게 현실로 다가오고 있습니다. 글로벌 반도체 기업들은 자사 칩셋에서 실용적인 Edge AI를 구현하기 위해 적극적으로 움직이고 있으며, NVIDIA 역시 최근 임베디드 자동차 및 로보틱스 애플리케이션을 위한 TensorRT Edge-LLM을 공개했습니다.
출처: NVIDIA GitHub
그동안 에너자이는 풀스택 Edge AI 솔루션 기업으로서, 1.58-bit 기술을 기반으로 실제 환경에 적용 가능한 고성능 AI 모델들을 구현해 왔는데요. 지금까지는 CPU, 특히 Arm CPU를 중심으로 한 배포에 주력해 왔습니다.
이번 글에서는 그 연장선에서 이룬 새로운 이정표를 소개하고자 합니다. 바로 1.58-bit 기술의 첫 비(非)CPU 구현 사례인데요. CPU를 넘어 임베디드 GPU 환경으로 1/58-bit 기술을 확장 적용하여 8B 규모의 Llama 모델을 8GB Jetson Orin Nano에서 구동하는 데 성공했습니다!
요약
오늘날 Edge AI에 기대되는 역할은 단순 기능 수행에서 스마트 AI 에이전트로 빠르게 변화하고 있습니다.
에너자이는 주어진 작업을 능동적으로 수행하고, 필요 시 외부 도구까지 호출할 수 있는 AI 에이전트를 구현하기 위해서는 최소 8B 수준의 모델이 필요하다고 보고 있습니다.
하지만 실제 AI를 Edge에 배포하는 과정에서 Edge SoC의 제한된 메모리 자원이 매우 큰 병목으로 작용하고 있습니다.
저희는 차별화된 1.58-bit 기술(양자화 및 커널 최적화) 기반으로, Jetson Orin Nano에서 8B Llama를 단 2.5GB 메모리만으로 구동하는 데 성공했습니다.
Capable Edge AI Needs Bigger Models
과거 Edge AI는 이상 탐지, 키워드 인식, 기본적인 명령 제어와 같이 비교적 간단한 작업들만 수행하는 것이 일반적이었는데요. 하지만 오늘날 Edge AI를 바라보는 시각은 다릅니다.
최근 NVIDIA 역시 Jetson 로컬 환경에서 LLM/VLM 및 파운데이션 모델을 행할 것을 권장하고 있으며, Use case도 개인용 AI 비서부터 완전 자율 로봇까지 폭넓게 제시하고 있습니다.

출처: NVIDIA
이러한 변화는 Edge에서 “쓸 만한 모델”의 기준 자체를 바꾸고 있습니다. 단순히 이벤트를 감지하거나 규칙 기반의 판단을 내리는 수준이라면 상대적으로 작은 모델로도 충분할 수 있습니다. 하지만 사용자의 질의에 대응하고, 문맥을 이해하며, 행동을 추천하고, 구조화된 자료까지 만들어야 한다면 좀 더 큰 모델이 필요한데요. 저희 경험상, 이러한 작업에서 안정적으로 유의미한 성능을 내기 위해서는 8B급 모델이 사실상 최소 수준에 가깝습니다. 물론 더 큰 모델이 더 나은 성능을 낼 수는 있지만, 임베디드 환경에서는 모델이 커질수록 배포 난이도가 급격히 상승합니다.
The Real Bottleneck: Memory
임베디드 하드웨어에서 LLM을 검토할 때 많은 팀이 먼저 연산 성능부터 확인합니다. 그러나 실제로는 연산량보다 메모리가 더 큰 제약 조건인 경우가 많습니다.
LLM을 구동하려면 단순히 모델 가중치만 저장하면 되는 것이 아닙니다. 런타임 버퍼, 중간 활성값, 그리고 특히 KV(Key-Value) 캐시를 위한 메모리도 필요합니다. KV 캐시는 생성 과정에서 모델이 입력 중 중요한 부분에 집중할 수 있도록 지원하는 중간 어텐션 정보를 저장하는 역할을 합니다. 그런데 이 캐시는 프롬프트 길이에 따라 선형적으로 증가하기 때문에, 컨텍스트 윈도우가 커질수록 매우 심각한 병목이 됩니다.
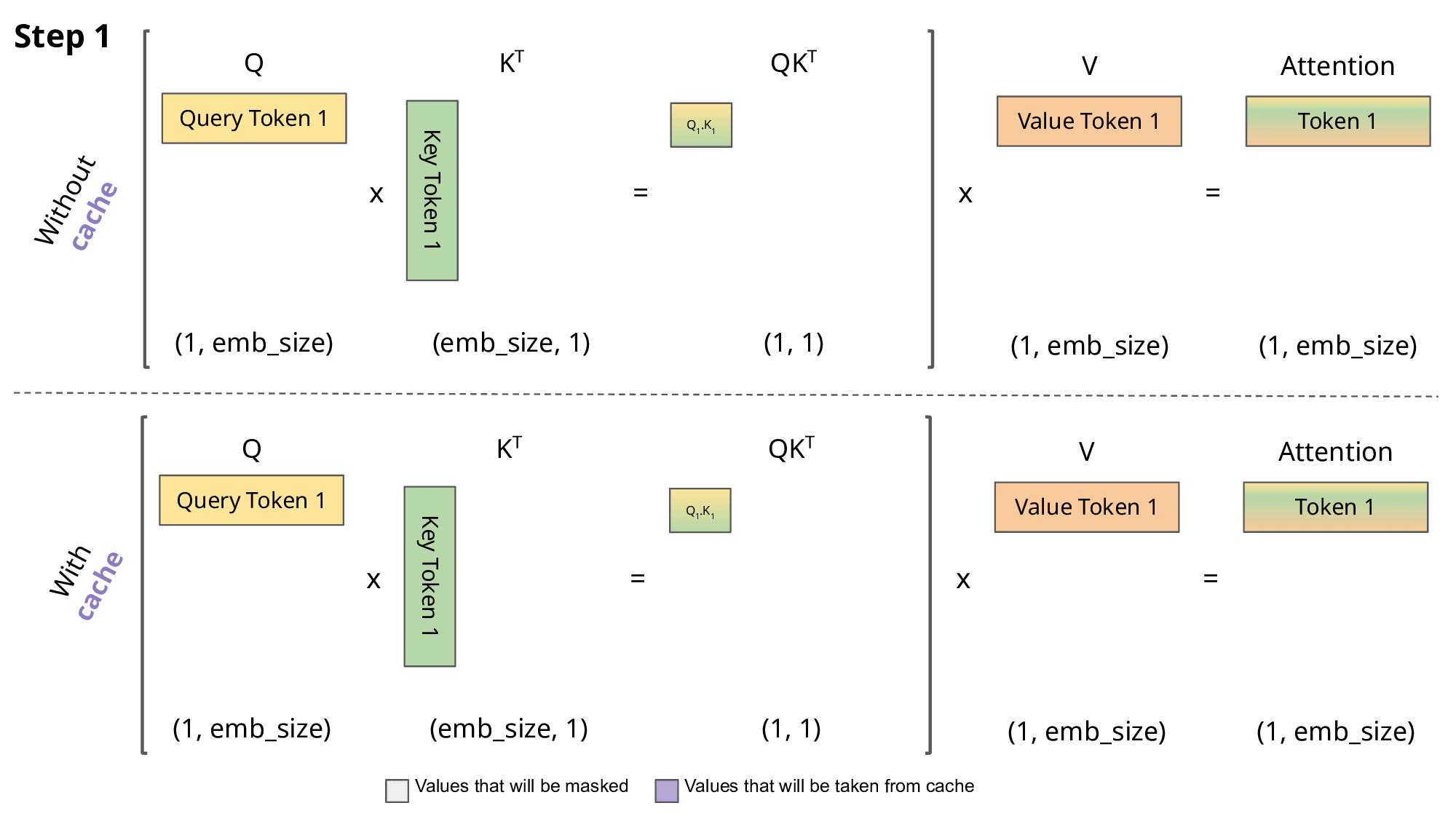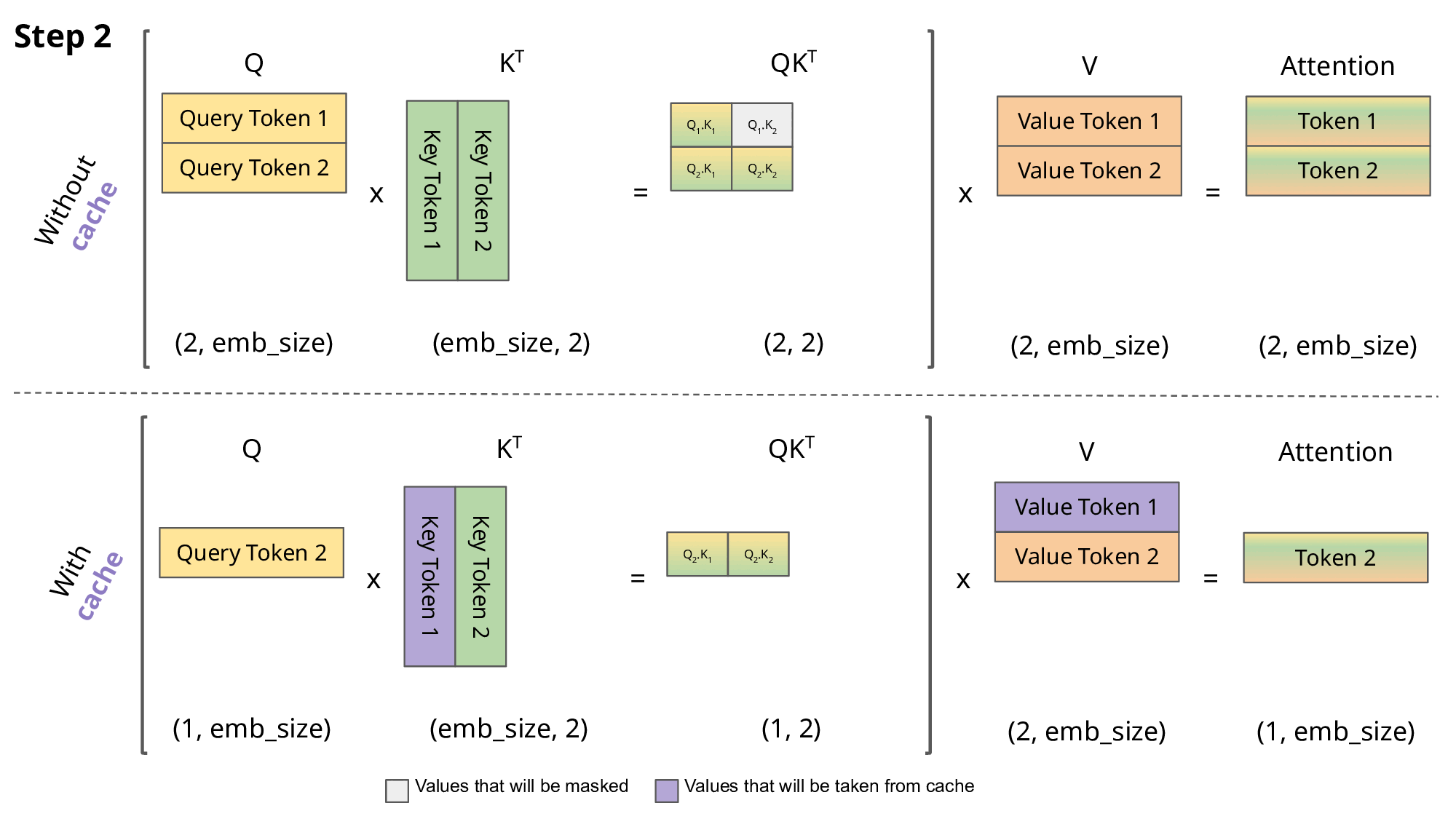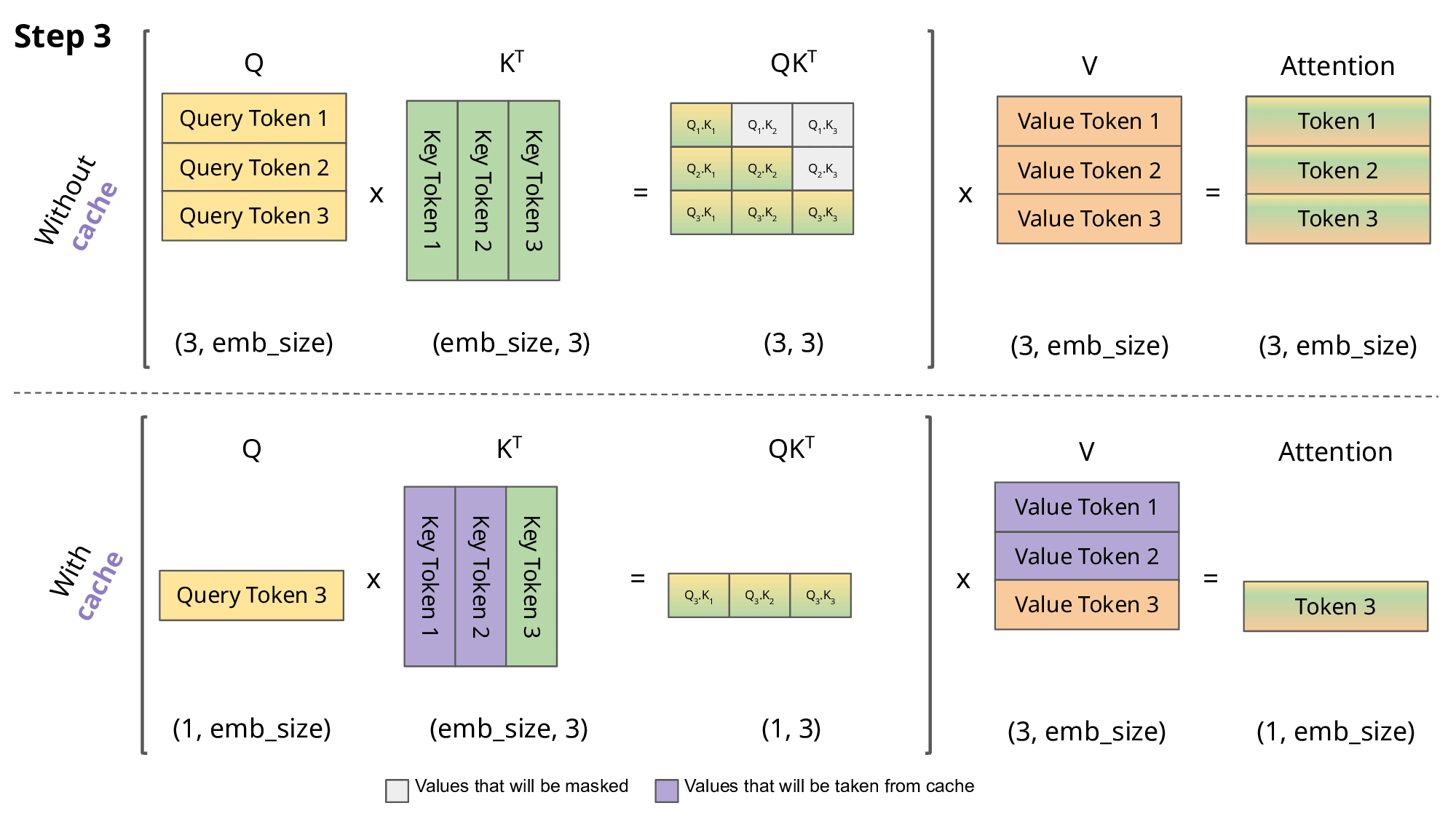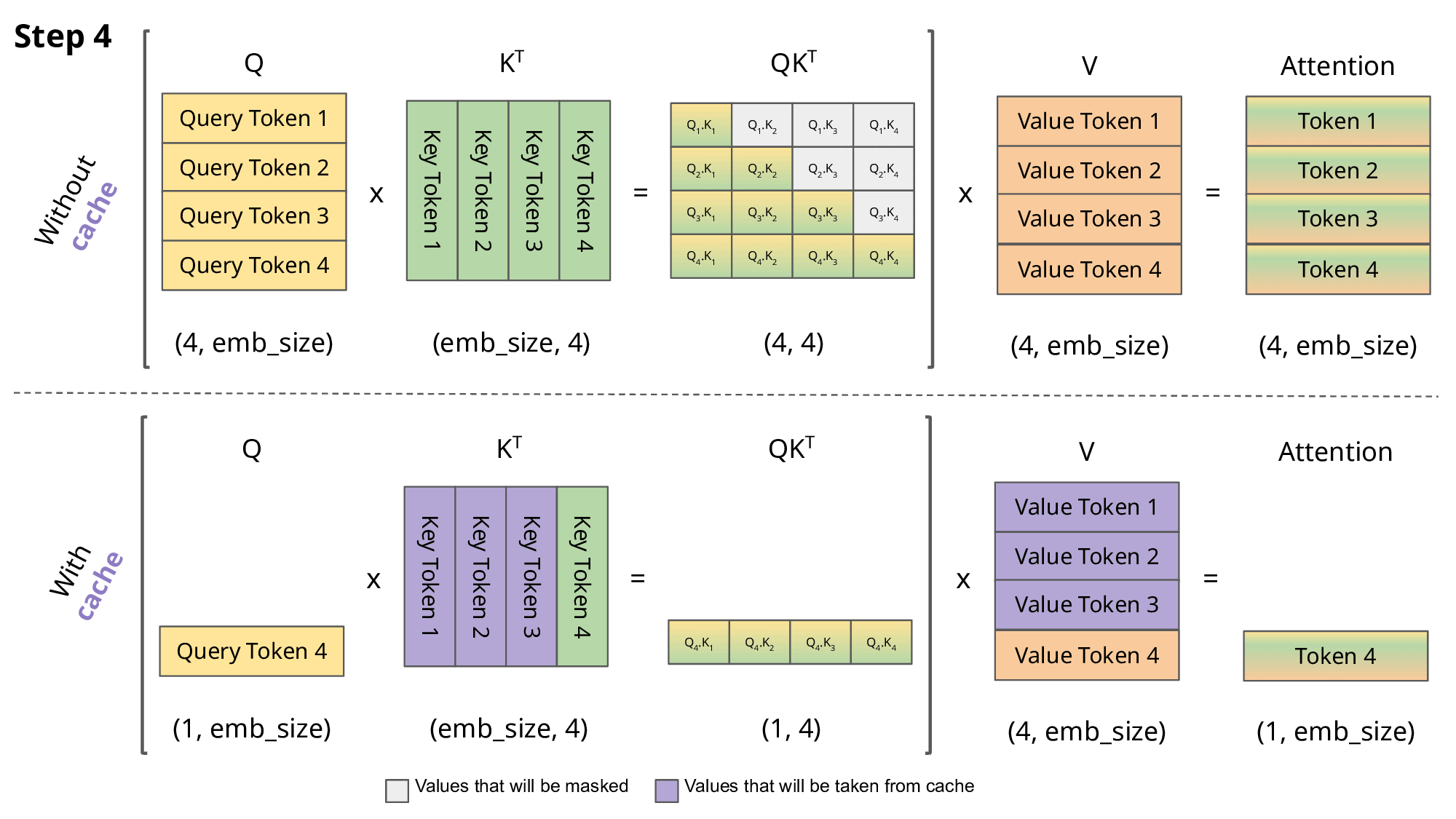
Source: https://medium.com/@joaolages/kv-caching-explained-276520203249
게다가 메모리는 LLM에만 전적으로 할당할 수 있는 자원이 아닙니다. 실제 Edge 애플리케이션에서는 인식, 네트워크, 텔레메트리, 로깅, 제어 로직, 운영체제 등 전체 스택이 모두 같은 메모리를 공유해야 합니다. 바로 이 점 때문에 메모리가 Edge AI 배포에서 가장 까다로운 병목이 되는데요. 모델은 전체 시스템의 일부일 뿐이지만, 적절히 제어하지 않으면 메모리 예산의 대부분을 순식간에 잠식할 수 있습니다.
Breaking the Memory Wall: Running 8B model on 8GB RAM
이처럼 큰 메모리 제약을 고려하면, 8GB Jetson Orin Nano에서 8B LLM을 실행하는 것은 결코 쉬운 목표가 아니었습니다. Baseline으로 설정한 llama.cpp 기반 Llama-3.1–8B-Q4조차도 GPU 메모리 5.2GB, 전체 RAM 기준으로는 최대 6.8GB가 필요했습니다. Jetson Orin Nano에서 실제로 사용할 수 있는 메모리가 약 7.4GB 수준이라는 점을 감안하면, 나머지 애플리케이션 스택이 사용할 수 있는 메모리 자원은 거의 남지 않는 것입니다.
이러한 점을 고려할 때, “구동 가능한 것”와 “실제 산업에서 활용 가능한 것”은 전혀 다른 문제입니다.
Lower Bits, Smarter Execution
결론부터 말하면, 저희는 Jetson Orin Nano에서 8B Llama 모델을 GPU 메모리 2.5GB, 전체 RAM 기준으로는 최대 4.1GB만을 사용하면서 구동하는 데 성공했습니다. Edge에서 하나의 LLM이 메모리 자원의 대부분을 사용하지 않으므로 다른 구성 요소들이 함께 동작할 수 있을 만큼의 여유 메모리를 확보할 수 있게 되었고, 이는 단순한 데모 시연을 넘어 실제 산업 현장에서 활용될 수 있는 고성능 Edge AI 시스템 구축에 한 발 더 나아간 고무적인 결과입니다.
이번에도 에너자이의 해답은 1.58-bit 기술이었는데요. 언어 모델을 1.58-bit로 양자화하고, Jetson 환경에서 극저비트 레이어들이 원활히 실행될 수 있도록 전용 커널을 구현했습니다.
목표는 단순히 모델을 최대한 강하게 압축하는 것이 아니었습니다. 핵심은 실제로 메모리 부담이 가장 큰 구간의 사용량을 줄이면서도, 모델의 성능은 보존하는 것이었습니다. 이를 위해 메모리 사용량이 큰 linear layer와 attention layer를 1.58-bit로 양자화해 메모리 압박을 크게 낮췄습니다. 동시에 mixed-precision 구조를 적용해, embedding과 LM head는 INT4로 유지함으로써 모델 성능 저하를 최소화했습니다. Mixed precision이 추론 성능을 어떻게 높이는지에 대해서는 이전 글에서도 다룬 바 있습니다.
Optimium 탐구(4) — Mixed Precision Inference
실행 측면에서는 INT4 embedding lookup, 1.58-bit GEMM(prefill), GEMV(generation)를 위한 커스텀 CUDA 커널을 구현했습니다. 또한 attention과 MLP(Gate+Up projection)에 대해 layer fusion을 적용해, 메모리 사용은 최소화하면서도 throughput(token/s)은 대화할 수 있도록 최적화했습니다.
Technical Implications
비용 절감
8B 모델을 훨씬 더 작은 메모리 예산 안에서 구동할 수 있다면, LLM 하나 때문에 고가의 하드웨어를 사용할 필요성이 줄어듭니다. 예를 들어, 기존에는 Jetson AGX나 NX가 필요했던 애플리케이션도 Nano급 디바이스에서 구현할 수 있습니다.더욱 풍부한 기능
임베디드 플랫폼에서 하나의 무거운 모델만 구동하는 대신, 개발자들은 STT + LLM + TTS로 구성된 로컬 음성 에이전트와 같이 보다 풍부한 온디바이스 AI 파이프라인을 설계할 수 있습니다.
Beyond Llama, Beyond Jetson
저희는 여전히 CPU가 AI 추론에서 중요한 역할을 할 것이라고 생각합니다. 하지만 진정한 Edge Intelligence로 가기 위해서는 CPU 뿐만 아니라 GPU와 NPU에서도 1-bit 모델을 실행할 수 있는 역량이 꼭 필요해질 것입니다.
바로 그렇기 때문에 이번 프로젝트는 에너자이에게 큰 의미를 지닙니다. 이번 프로젝트는 단순히 Jetson Orin Nano에서 8B 모델 하나를 실행한 것이 아니라 저희의 1.58-bit 기술을 CPU 외에 임베디드 GPU 환경으로 처음 확장한 사례이며, 이를 통해 다양한 Edge SoC로의 확장 가능성을 제시했다는 데 더 큰 의미가 있습니다.
실제로 저희는 이미 Qualcomm Hexagon 환경에서 자체 1.58-bit 모델을 배포하기 위한 작업도 진행 중인데요. 앞으로는 지원 범위를 한층 더 확장해 Broadcom, Synaptics를 비롯한 다양한 하드웨어 플랫폼에서 극저비트 모델이 실용적인 방식으로 배포될 수 있도록 발전시켜 나갈 계획입니다.
ENERZAi at GTC
이 글을 작성하는 현재, GTC 2026이 진행 중이며, ENERZAi는 이번 프로젝트를 포스터 세션에서 소개할 수 있는 기회를 얻게 되어 매우 뜻깊게 생각하고 있습니다. 저희 팀은 현재 미국 산호세(San Jose) 현장에서 직접 연구 성과를 공유하고 있습니다.


에너자이는 GTC를 포함한 다양한 글로벌 전시회 및 컨퍼런스에 활발히 참여하며 산업 전반의 리딩 기업들과 적극적으로 교류하고 있습니다. Edge에서 True AI Intelligence를 구현하고자 하는 1-bit pioneer로서 에너자이의 여정이 궁금하시다면 언제든 편히 연락 부탁드립니다!