October 24, 2025
On October 21, Arm hosted the 'Arm Unlocked Korea 2025' to collaborate with global AI semiconductor partners and the industrial ecosystem.

On October 21, Arm hosted the 'Arm Unlocked Korea 2025' to collaborate with global AI semiconductor partners and the industrial ecosystem. Arm Unlocked Korea succeeds the Arm Tech Symposia. While previous events focused on semiconductor asset-related technology, the future focus will be on comprehensive themes such as AI leadership and AI computing transition. This marks a shift from Arm's past strategy of solely providing design licenses to expanding its influence into data centers and AI infrastructure, designing chips directly, and competing in the market.
Participation of Domestic and International Arm Partners in Automotive, Infrastructure, and Consumer Sectors

A session on AI model quantization for Arm-based devices was held at Arm Unlocked Korea 2025 on October 21 / Source=IT Donga
In April, Arm diversified its approach to the semiconductor market by segmenting its computing sub-system (CSS) brand, which previously only included 'Neoverse' for servers, into ▲Neoverse for servers ▲Niva for PCs ▲Zena for automotive ▲Orbis for IoT ▲Lumex for mobile.
Accordingly, Arm Unlocked Korea was also divided into three sectors: ▲Automotive, including Arm Zena and chiplet architecture, virtual platforms ▲Infrastructure, covering Arm CSS, Neoverse CSS, modular firmware, chiplet integration ▲Consumer Devices, dealing with Armv9 CPU and GPU, SME2, and systems.

Sessions were largely divided into automotive, infrastructure, and consumer devices, with the highest participation in consumer devices for general user devices / Source=IT Donga
The session saw participation from major companies such as Siemens Korea, Cadence Design Systems, LG Electronics, Synopsys, Samsung Electronics, KT Cloud, as well as numerous domestic and international Arm semiconductor-related companies like Asicland, Telechips, StradVision, CoAsia, Gaonchips, and Hailo. Enerzai was the only startup to take the stage among these prominent semiconductor companies, highlighting Arm's intent to expand its ecosystem, especially as Enerzai is a software company rather than a hardware or semiconductor company.
ENERZAi was selected for the 'Arm AI Partner Program' in 2022 as a company specializing in AI model quantization technology / Source=ENERZAi
Enerzai is developing model quantization technology that compresses AI models enough to process AI on edge devices or smartphones independently, and an AI inference optimization engine called Optimium. As the utilization of large language models (LLM), voice models, and translation models increases, there is a push to introduce AI into smartphones, laptops, or smaller devices, but performance constraints of the devices pose challenges. Even running Meta's Llama 3.1-8B, which is relatively small for a large language model, requires system memory of 16GB and video memory of around 12GB, similar to the latest laptops.
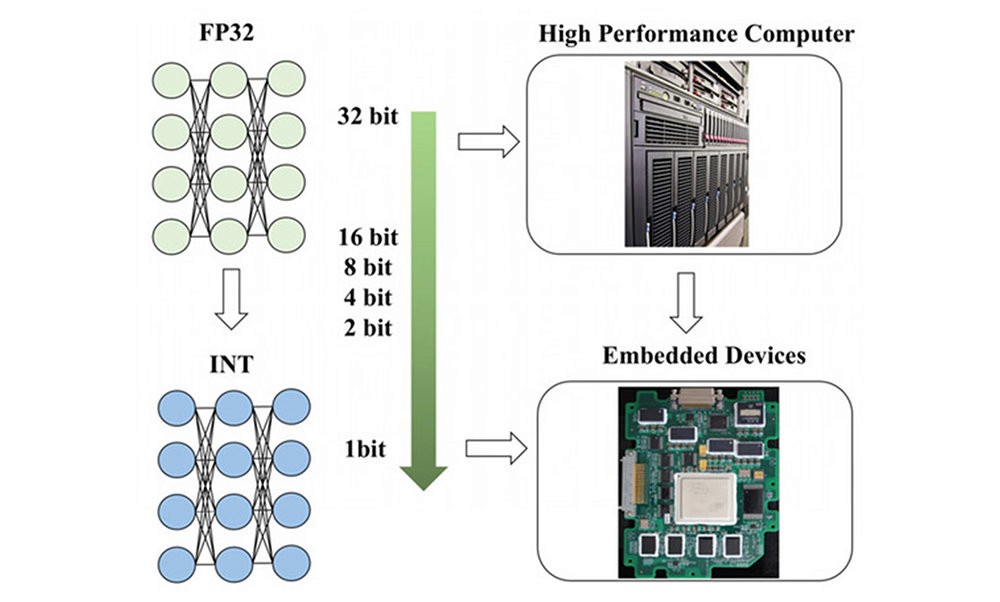
General AI models are 32-bit, but to run models smoothly on small devices with performance limitations, quantization to reduce capacity and specifications is necessary / Source=Advances in the Neural Network Quantization: A Comprehensive Review
The industry is developing technology to reduce computation and capacity by converting precise real numbers to shorter integers when processing AI model calculations, while maintaining maximum performance. This can be simply referred to as compression technology, known in industry terms as 'model quantization.' General AI models are made with 32-bit floating points (float32), and reducing them to 8-bit decreases memory usage by about four times and increases processing speed by two to four times.
Further quantizing to 2-bit reduces the Llama 3.1 8B AI model's size from 28GB to about 2GB, and memory to 5-8GB, allowing it to run on smartphones. While model performance is somewhat lost, the requirement for specifications and capacity is significantly reduced. Extreme quantization refers to anything below 4-bit, and Enerzai is developing technology with a 1.58-bit quantization algorithm to enable AI models to run fully on low-power, ultra-small devices.
AI Optimization Needed by LG Electronics, Addressed by Enerzai
Enerzai participated in the 'Expansion of On-Device AI across Various Arm Ecosystems' session in the consumer devices sector. The presentation involved a discussion between Woo Sung-ho, an LG Electronics research fellow from the AI system software team for webOS, the operating system of LG Electronics televisions, Lee In-cheol, LG Electronics team leader, and Jang Han-him, CEO of Enerzai, about the AI development and deployment process on Arm System-on-Chip (SoC) based LG smart TVs and how model quantization can overcome challenges.

From left: Jihee Hwang, Director at Arm, Woo Sung-ho, LG Electronics Research Fellow, Lee In-cheol, LG Electronics Team Leader, Jang Han-him, CEO of ENERZAi / Source=IT Donga
Lee In-cheol stated, “Today, many LG appliances integrate AI. The goal is for appliances to configure themselves according to consumer needs and even offer proactive services. However, the challenge lies in achieving this across devices with varying performance levels, from budget to premium, with limited specifications. Quantization allows AI models to be lightweight and optimized for application across various devices,” adding, “Even webOS TVs, with over 200 million units, are upgraded over five years. Products equipped with Arm SoC can be managed integrally using KleidiAI, achieving optimal business efficiency.” KleidiAI is a tool that helps run and optimize AI on Arm-based devices.
Woo Sung-ho also commented, “AI experienced by customers is advancing, and expectations are rising. Now, even appliances implement large language models with 2.4B (2.4 billion parameters), and it’s important to offer more features even if there’s some quality loss.” He continued, “Some models experience significant performance drops just by changing from 32-bit to 8-bit. It’s not a problem that can be solved with a single technique or specific model. Many experiments, attempts, and know-how are crucial. Combining LG Electronics’ product pipeline with Enerzai’s lightweight know-how will create significant synergy.”

Jang Han-him, CEO, explains Enerzai’s quantization process and how to utilize the Optimium engine / Source=IT Donga
Enerzai seeks to find the optimal balance to preserve performance as much as possible, considering different hardware specs for each device and the loss of accuracy during AI quantization. They apply a combination of post-training quantization (PTQ), which is done after model construction, and quantization-aware training (QAT), which maintains performance through additional training, to find the optimal values.
Jang Han-him stated, “Before executing a project, we set the customer’s goals and requirements, and through numerous experiments, we diagram accuracy and efficiency. PTQ is good in terms of development cost and speed, but 4-bit is the limit. Below that, we secure performance through QAT while quantizing. Enerzai quantizes down to 1.58-bit based on QAT. Considering cost and speed, we aim to implement ultra-fine quantization based on PTQ in the future. By combining results from various quantization approaches, we derive a performance-efficiency balance curve for optimization.”
Screen demonstrating the process of quantizing an LSTM (Long Short-Term Memory) based deep learning model / Source=Arm
ENERZAi has experience in commercially deploying optimized lightweight language models, operating within 100MB, to millions of devices according to customer needs, and has also worked on assigning AI to run on CPUs instead of neural processing units (NPUs) to secure real-time performance using Optimium. They are also accumulating cases of implementing AI models using Arm SoCs in automotive and collecting data from medical devices running on Arm-based devices for participation in diagnostic processes.
Introducing Methods for AI Distributed Work by CPU, GPU, and NPU

Woo Sung-ho, LG Electronics Research Fellow, shares thoughts on resource allocation related to NPU, GPU, CPU / Source=IT Donga
Jang Han-him stated, “An approach is needed where tasks are assigned three-dimensionally to components suitable for each, rather than assigning an entire model to one. For example, when live streaming YouTube with a micro SoC, video is processed by the CPU, while the process of converting audio to text and then to subtitles is assigned to the NPU. This allows for optimal task assignment and finding the best balance between model performance and memory efficiency.”
Woo Sung-ho also added, “While the AI processing performance of GPUs is the highest, they are expensive in terms of power efficiency and cost. In low-power environments, it will become important to efficiently configure AI models themselves or make good use of NPUs. Currently, resource allocation for CPU, NPU, and GPU is done statically, but in the future, these elements may evolve to operate in a composite manner for stability, efficiency, and acceleration.”
The 'Solution' to Capture Both Cost and Efficiency in Extreme Optimization
Extreme optimization methods like 1.58-bit quantization are solutions for implementing AI in ultra-small computing systems like edge computers. In other words, it is a technology to efficiently run AI even on low-performance computers and maximize AI performance with higher computational efficiency using the same system resources. It involves not only compressing models but also assigning commands three-dimensionally according to the processing efficiency of CPU, NPU, and GPU, finding the optimal values that satisfy different chips, and advancing extreme optimization technology.
The need for extreme optimization arises because users familiar with AI can clearly perceive a drop in model performance. Many users immediately notice the gap between GPT-4 and GPT-5. In the past, a TV five years old was just an old product, but a TV equipped with AI must continue to evolve in performance over time to avoid being ignored by consumers.

Even LG Electronics televisions, which were featured as examples in this presentation, are fragmented into hundreds of models with varying performance, numbering in the hundreds of millions. All products must be updated to deliver optimal performance, and AI models must evolve in line with trends to survive in the long term. However, since the CPU and memory performance of televisions from a few years ago will not change, improving AI efficiency through model quantization is the optimal solution. In this regard, ENERZAi’s technology and know-how are technologies that the entire IT industry, including LG Electronics, is focusing on, and this is why Arm is collaborating with them.