
Technology
안녕하세요, 에너자이입니다. 오늘은 저희 팀이 이뤄낸 작지만 의미 있는 성과를 공유하려고 하는데요. 에너자이가 QNN 기반으로 Qualcomm QCS6490 Hexagon NPU에 BitNet (b1.58) 2B를 배포하는데 성공했습니다!
Sungmin Woo
2026년 4월 17일
안녕하세요, 에너자이입니다. 오늘은 저희 팀이 이뤄낸 작지만 의미 있는 성과를 공유하려고 하는데요. 에너자이가 QNN 기반으로 Qualcomm QCS6490 Hexagon NPU에 BitNet (b1.58) 2B를 배포하는데 성공했습니다!
비교적 낯설게 느껴지는 용어들이 꽤 많이 등장할 수 있지만 걱정하지 마세요. 이 글을 다 읽고 나면 왜 저희가 이번 연구를 온디바이스 AI의 새로운 가능성을 제시한 의미 있는 연구라고 말하는지 이해하시게 될 것입니다.
요약
BitNet b1.58은 Microsoft Research가 개발한 아키텍처로, 가중치를 ternary 값(−1, 0, +1)으로 표현합니다. 이로 인해 모델이 매우 가볍기 때문에 메모리/연산 자원이 제약된 온디바이스 환경에 배포할 때 매우 효과적입니다.
Qualcomm의 QNN을 포함한 대부분의 NPU SDK는 표준적인 양자화 포맷들만 지원합니다. BitNet의 Ternary 연산들은 지원되지 않기 때문에, 현 시점에서는 BitNet을 NPU에서 실행할 방법이 없습니다.
에너자이는 Qualcomm Hexagon 아키텍처에 특화된 1.58-bit 커널들을 자체적으로 구현하여, Qualcomm QCS6490 Hexagon NPU에서 BitNet (b1.58) 2B를 합리적인 메모리 사용량과 throughput으로 구동하는 데 성공했습니다.
저희는 온디바이스 환경에서 true intelligence를 구현하기 위해서는 최소 8B 이상의 모델이 필요하다고 보고 있습니다. 이번 성과는 NPU에서 이러한 고성능 모델을 구동할 수 있다는 가능성을 제시한 작지만 의미 있는 결과입니다.
BitNet (b1.58)이란?
하드웨어 이야기로 넘어가기 전에, BitNet이 무엇인지 간단히 살펴보겠습니다.

BitNet은 Microsoft Research가 발표한 LLM 아키텍처로, 모델 가중치를 표현하는 방식을 근본적으로 바꾼 연구입니다. BitNet b1.58에서 가중치는 −1, 0, +1, 단 세 가지 값으로만 표현되고, 이를 ternary 가중치라고 부르는데요. “b1.58”로 표현하는 이유는 세 가지 상태를 표현하는 데 이론적으로 필요한 최소 비트 수가 log₂(3) ≈ 1.58이기 때문입니다.
이처럼 매우 적은 비트로 표현된 BitNet은 최소한의 메모리로 구동될 수 있기 때문에 자원이 제약된 온디바이스 환경에 매우 적합합니다. 저희가 자체적으로 진행한 1.58-bit 양자화 연구도 이전 포스트에서 상세히 다룬 바 있으니, 관련 내용이 궁금하시다면 아래 링크를 참고해 주세요!
AI 모델을 위한 위고비 💉 — 1.58-bit 양자화에 대하여
오늘 이야기의 핵심은, 이 BitNet을 실제 Edge에서 구동하려고 할 때 어떤 일이 벌어지는가입니다.
장기적으로 온디바이스 LLM에 NPU가 필요한 이유
NPU(Neural Processing Unit)는 AI 추론에 특화된 프로세서입니다. CPU와 같은 범용 연산장치들과는 다르게 대규모 행렬 연산, activation function, 그리고 현대 LLM의 핵심인 attention 메커니즘 등 신경망 연산들에 대하여 최적의 성능을 낼 수 있도록 설계되었는데요.

출처: DT Research
이 차이는 온디바이스 환경에서 실질적인 이점으로 이어집니다. 온디바이스 AI를 구현할 때 가장 큰 병목이 되는 것은 메모리이지만, NPU는 메모리뿐만 아니라 전력 측면에서도 다른 연산장치들보다 높은 효율을 내는 것이 가능하며, 이는 배터리 기반으로 구동되는 디바이스들에 대해서는 결정적으로 작용할 수 있는 이점입니다. 뿐만 아니라, AI 연산을 가장 잘 수행할 수 있도록 설계된 칩이므로, 연산 과정에서 발생하는 latency도 최소화되어 훨씬 더 자연스러운 상호 작용을 지원합니다.
에너자이는 지금까지 주로 CPU에 1.58-bit 기술을 적용해왔는데요. 저희는 장기적으로도 주어진 하드웨어 자원을 가장 효율적으로 활용할 수 있다는 점에서는 여전히 의미 있는 접근이라고 보고 있습니다. 하지만 온디바이스 환경에서 진정한 intelligence를 구현하기 위해 필요한 대규모 모델을 실행하려면, 결국 NPU가 필요한데요. 문제는 그 과정이 순탄하지 않다는 데 있습니다.
SDK의 한계, 그리고 BitNet의 높은 벽
NPU에 모델을 올리는 것은 파일을 복사해서 실행하는 것처럼 단순하지 않습니다. 모든 칩 제조사는 자사 하드웨어에서 실행 가능한 연산과 레이어 타입을 정의하는 SDK를 제공하는데, Qualcomm의 경우 이것이 QNN(Qualcomm Neural Network)입니다.
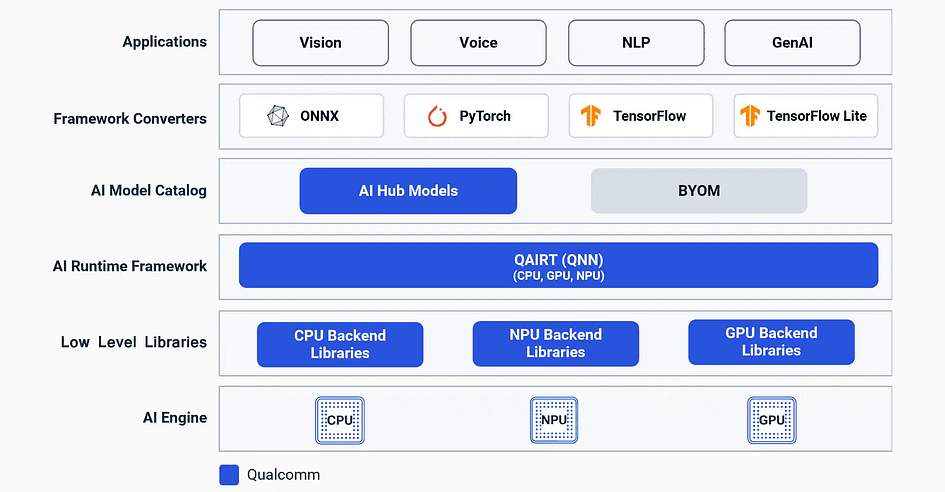
출처: Qualcomm
QNN은 일반적인 transformer 레이어, INT8/INT4 양자화 등 표준적인 연산들을 폭넓게 지원합니다. 하지만 여기서 핵심은 “표준적인”이라는 단어입니다. NPU SDK는 본질적으로 보수적인 성격이 강하기 때문에 충분히 검증된 것들만 지원하며, 최신 연구를 유연하게 지원하는 경우는 거의 없습니다.
그리고 BitNet은 이러한 지원 범위에서 완전히 벗어나 있습니다. QNN이 ternary, 즉 1.58-bit를 지원하지 않으므로, BitNet의 우수한 메모리 효율 및 빠른 속도의 핵심인 ternary 행렬 곱셈 연산들이 QNN 레이어 라이브러리 어디에도 존재하지 않습니다. 실행 경로 자체가 없는 것입니다.
이는 온디바이스 AI를 연구하는 대부분의 팀들이 마주하는 문제이며, BitNet처럼 새로운 구조의 혁신적인 모델일수록 더 해결하기 어려운 문제입니다.
How We Did It: 자체 Hexagon 커널 구현
저희는 QNN이 BitNet을 지원할 때까지 기다리는 대신, 직접 실행 경로를 만들기로 결심했습니다.
Qualcomm의 Hexagon 아키텍처는 개발자들에게 극히 일부 영역에 한정하여 low-level 인터페이스를 열어두고 있습니다. 넓게 열린 문은 아니지만, 저희는 그 좁은 틈을 발판으로 삼아 1.58-bit 연산을 위해 설계된 Hexagon 커널들을 직접 구현했습니다.
여기서 “커널”이란 하드웨어가 연산을 실제로 수행하는 방식을 정의한 low-level 실행 코드를 뜻하는데요. Chip SDK가 지원하지 않는 연산들에 대해 직접 커널을 만드는 것은 하드웨어/소프트웨어 양쪽에 대한 깊은 이해를 필요로 하는 설계 작업이기 때문에 매우 정밀하고 손이 많이 가는 작업입니다. 그리고 에너자이는 이러한 도전을 통해 온디바이스 AI의 최전선을 직접 개척하고 있습니다.
그리고 마침내 Qualcomm QCS6490 Hexagon NPU(Adreno GPU 포함)에서 BitNet (b1.58) 2B를 합리적인 메모리 사용량과 throughput으로 구동하는 데 성공했습니다!
Beyond a Single Chip
BitNet이라는 모델을 Hexagon NPU에서 구동했다는 성과 자체만으로도 의미가 있지만, 조금 더 넓은 관점에서 보면 보다 흥미로운 점들을 발견할 수 있습니다.
사실 Hexagon만 고려했을 때도 Hexagon이 탑재된 Qualcomm의 Snapdragon 플랫폼은 세계에서 가장 많이 보급된 컴퓨팅 플랫폼 중 하나입니다. 현재 수십억 대의 스마트폰, AR/VR 헤드셋, 자동차 시스템 등에 탑재되어 있는데요.

출처: Qualcomm
다시 말해, Hexagon NPU에서 BitNet과 같은 극저비트 언어 모델을 실행할 수 있다는 것은 특정 기기 하나에 국한된 이야기가 아닙니다. 사람들이 주머니 속에, 손목 위에, 그리고 자동차 안에 이미 갖고 있는 방대한 하드웨어 생태계 전체를 여는 열쇠가 될 수 있습니다.
Scalable한 온디바이스 AI를 구현하기 위해서는 하드웨어 성능도 물론 중요하지만, 그 이상으로 소프트웨어 side의 혁신이 필요합니다. 에너자이는 그 답을 찾기 위한 과정의 일환으로 연구 단계에서 머무르는 것이 아니라 실제 산업에 활용될 수 있는 극저비트 저메모리 모델을 만들고 있습니다.
온디바이스 True Intelligence를 향해
이전 포스트에서도 말씀드렸듯이, 궁극적으로 저희는 온디바이스 환경에서도 문맥을 이해하고, 필요한 작업을 스스로 판단하고, 적절한 도구를 자율적으로 호출할 수 있는 모델을 구현하고자 합니다. 이처럼 proactive한 고성능 모델을 구현하기 위해서는 최소 8B 규모의 모델이 필요할 것으로 보고 있는데요.
BitNet 2B는 저희가 장기적으로 추구하는 수준의 성능을 낼 수 있는 모델은 아닙니다. 하지만 이번 성과는 온디바이스 환경에서의 NPU 기반 LLM 추론에 대한 가능성을 증명했다는데 의미가 있으며, 에너자이 팀에게는 저희 연구개발 방향성에 대한 확신을 다시 한 번 되새기는 계기가 될 수 있었습니.
저희는 앞으로도 더 많은 모델과 더 다양한 하드웨어 플랫폼으로 지원 범위를 넓혀갈 예정입니다. 에너자이의 1.58-bit 기술이 궁금하시거나, 여러분의 플랫폼에서 온디바이스 AI를 어떻게 활용할 수 있을지 함께 이야기해보고 싶으시다면 편하게 연락 주세요!