
Technology
Today, we are excited to share a milestone that our team has been working toward for some time. ENERZAi has successfully deployed BitNet (b1.58) 2B on the Qualcomm QCS6490 Hexagon NPU via QNN!
Sungmin Woo
2026년 4월 17일
Today, we are excited to share a milestone that our team has been working toward for some time. ENERZAi has successfully deployed BitNet (b1.58) 2B on the Qualcomm QCS6490 Hexagon NPU via QNN!
If that sentence felt like a lot of acronyms, don’t worry. By the end of this post, you’ll understand exactly why this matters, why it was so difficult, and why we believe it points toward a meaningful shift in what’s possible with AI on edge devices.
TL;DR
BitNet b1.58 is an architecture by Microsoft Research represented in ternary values (−1, 0, +1), making it exceptionally compact and well-suited for edge deployment.
Most NPU SDKs, including Qualcomm’s QNN, only support standard quantization formats. BitNet’s ternary operations are not supported, meaning no execution path on NPU exists out of the box.
With custom 1.58-bit kernels for Qualcomm’s Hexagon architecture, ENERZAi successfully ran BitNet (b1.58) 2B on the Qualcomm QCS6490 Hexagon NPU with reasonable memory and throughput.
This is an early but meaningful proof of concept on the path toward running >8B models on NPU, the scale we believe is necessary for true edge intelligence.
A Quick Refresher: What Is BitNet (b1.58)?
Before we dive into the hardware side, let’s make sure we’re on the same page about BitNet.

BitNet is a large language model architecture introduced by Microsoft Research that rethinks how model weights are represented from the ground up. BitNet b1.58 constrains weights in the model to one of only three possible values: −1, 0, or +1. These are called ternary weights. The “1.58” comes from information theory: log₂(3) ≈ 1.58, which is the minimum number of bits theoretically needed to represent three distinct states.
It is a model exceptionally well-suited for edge deployment with tiny memory footprint. We’ve also written extensively about our own 1.58-bit quantization work in previous posts. If you’d like a deeper technical dive, check those out.
1.58-bit Quantization — the Wegovy for AI models 💉
Today, the focus is on what happens when you try to run BitNet on real edge hardware.
Why we need NPU for Edge LLMs in the long run
An NPU, or Neural Processing Unit, is a chip designed from the ground up specifically for AI inference workloads. Unlike general-purpose processors, its circuit architecture is optimized for the kinds of operations that dominate neural network computation including large-scale matrix multiplications, activation functions, and the attention mechanisms at the heart of modern LLMs.

Source: DT Research
This specialization translates directly into real-world advantages that matter enormously at the edge. Not only in terms of memory, NPUs deliver the same inference throughput at a fraction of the energy cost compared to other processing options, a decisive advantage in battery-powered devices where power budgets are tight. And the dedicated hardware pipelines enable minimized latency, making real-time interaction feel natural.
ENERZAi has primarily applied its 1.58-bit technology to the CPU, and this remains meaningful in that it makes the most efficient use of available hardware resources. However, running the large models necessary to achieve true intelligence at the edge ultimately requires the NPU. The challenge is getting there.
The Problem: Most SDKs Can’t Keep Up and BitNet Makes It Harder
Deploying a model on an NPU isn’t as simple as copying it over and pressing run. Every chip vendor provides an SDK, a software toolkit that defines exactly which operations and layer types the hardware will execute. Qualcomm’s SDK is called QNN (Qualcomm Neural Network).
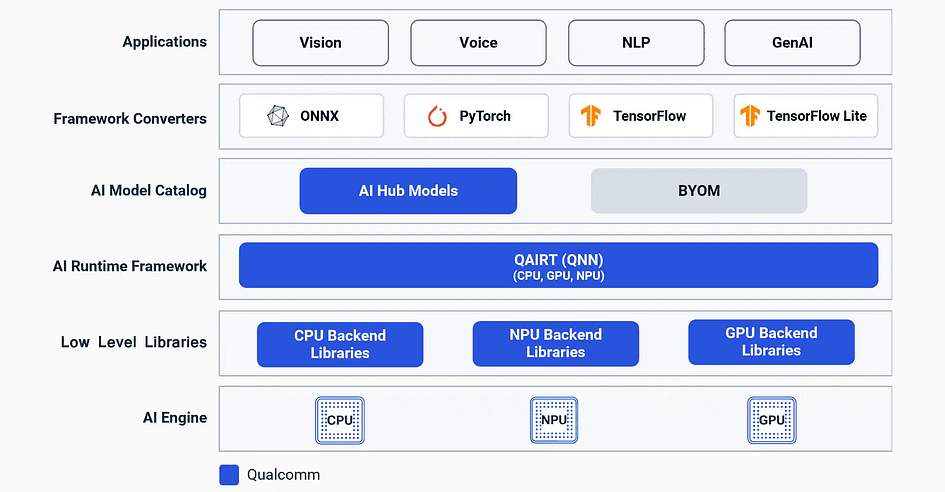
Source: Qualcomm
QNN supports a solid range of standard operations: common transformer layers, INT8 and INT4 quantization, and the building blocks of most mainstream models. But “most mainstream models” is the key phrase. The reality is that NPU SDKs are inherently conservative. They support what has been broadly validated, not what’s cutting-edge.
BitNet sits firmly outside that list. QNN has no support for ternary, 1.58-bit operations. The ternary matrix multiplications that are central to how BitNet works, the very thing that makes it so memory-efficient and fast, don’t exist anywhere in QNN’s layer library. It’s not a matter of configuration or workarounds. The execution path does not exist.
This is the wall that most teams hit. And for a model as unconventional as BitNet, the wall arrives even sooner than usual.
How We Did It: Custom Hexagon Kernels
Instead of waiting for QNN to support BitNet, we built the execution path ourselves.
Qualcomm’s Hexagon architecture does leave a minimal surface area of lower-level interfaces open for developers. It’s not a wide-open door, but it’s enough of a foothold to build on. On top of that foundation, we engineered our own custom Hexagon kernels specifically designed for 1.58-bit operations.
A “kernel” in this context is the low-level computational routine that the hardware actually executes. Writing a custom kernel is painstaking work. But it’s also the kind of deep hardware-software co-design that separates teams who can push the frontier from those who are waiting for someone else to push it for them.
And finally we did it! Running BitNet (b1.58) 2B on the Qualcomm QCS6490 Hexagon NPU (with Adreno GPU) with reasonable memory and throughput.
Why This Matters Beyond a Single Chip
This result is significant on its own merits. But zoom out, and the picture becomes even more compelling.
Qualcomm’s Snapdragon platform, the family of chips that includes the Hexagon NPU, is one of the most widely deployed computing units in the world. It powers billions of smartphones, AR/VR headsets, and automotive systems.

Source: Qualcomm
This means that the ability to run capable, low-bit language models on the Hexagon NPU is not a niche capability for a single device category. It’s a key that unlocks a vast, already-deployed ecosystem of hardware that people carry in their pockets, wear on their wrists, and drive inside.
The question of where edge AI will actually run at scale is partly a software question. And right now, we’re helping write that software.
The Road Toward True Edge Intelligence
As we’ve discussed in previous posts, we believe that models at roughly the 8B parameter scale represent a meaningful threshold for what we call “true edge intelligence”, models capable of understanding context, determining what task is needed, and calling the right tools autonomously. The proactive AI behaviors that make a device genuinely useful rather than just responsive.
BitNet 2B is below that threshold, but this deployment is an important proof of concept. It demonstrates that the technical path to NPU-based LLM inference is open, and it gives us deep confidence in our approach.
We will continue expanding support across more models and more hardware platforms. If you’d like to learn more about ENERZAi’s 1.58-bit technology or explore what edge AI could look like for your platform, feel free to reach out to us! We’d love to talk.